

Distributed Server Allocation
Allocation of servers for different components used by applications in a distributed, fault-tolerant and secure manner, resulting in high availability, compliance and self-heal capabilities of applications running in a private cloud
Worked On
UX, UI, Backend service, Allocation Logic
Tech Stack
Java + Struts, MySQL, VanillaJS
Date
May, 2017
Challenge
Servers can be grouped based on types (VM/PS), hardware configs (RAM, Disk Type, Storage), IP Subnets (CIDR/VPC), Compliance (SOC/HIPAA), OS (Linux/Windows/Unix) and so on. Allocating different servers depending on the component for which they perform efficiently and to be aware of unforeseen failures like power outages, fire-incident at the rack level, KVM host issues and have self-heal capabilities, resulting in very low downtime for applications.
Solution
An algorithm that takes into account the desired configurations and other variable factors into account, thereby allocating servers in a distributed way, providing a guarantee that it is highly performant, fault-tolerant and standard-compliant.
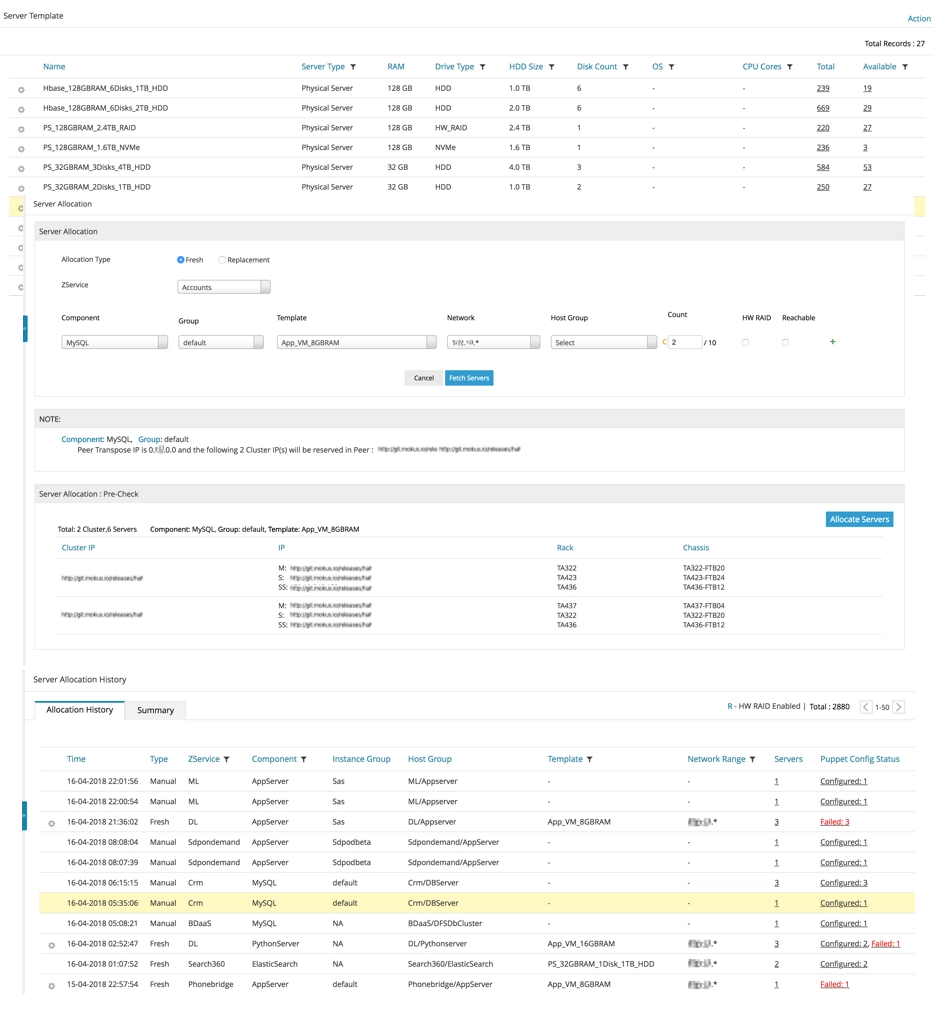
About Server Allocation
To host more than a single application/database, we usually procure separate clusters for each. To host it in the private cloud, we need to allocate the servers in a manner that is rack & chassis aware, leading to minimal outages due to hardware failures within a cage.
Problem
Manual allocations were very slow and inefficient. Sometimes, unreachable nodes were being allotted. This resulted in a delay in server provisioning and the launch of a product. Unavailability of IPs in the desired VPC/CIDR range caused delays.
How I solved this?
I came up with a proprietary algorithm that allocates servers dynamically across racks, chassis and physical servers based on required hardware specs and CIDR Subnets. This also ensured that the allocated servers were reachable, void of hardware & software issues and compliant with the VPC separation.
I boosted it further by templatizing the workflows and the applications could be mapped to certain templates with desired configurations. This was then used to allocate web servers, application servers, database clusters and big-data services as well, covering all the components required for a product release and making the server provisioning very efficient and quick.
Impact
- Server provisioning time got reduced from ~ 1 day to less than a minute #agility #1500X_improvement
- This increased the fault-tolerance capability during outages caused by power failures at rack/chassis level #robust
- During nodes fail-over, an immediate replacement will be performed automatically, resulting in highly available servers for the application #high_availability #self_heal
- Infra cost metrics associated with each team could be easily identified and scaled-down based on usage #cost_aware_business